Optimizing Over Multiple Objectives¶
Chocolate offers multi-objective optimization. This means you can optimize the precision and recall without averaging them in a f1 score or even the precision and inference time of a model! Lets go straight to how to do that. First, as always, import we import the necessary modules.
from sklearn.datasets import make_classification
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import precision_score, recall_score
from sklearn.model_selection import train_test_split
import chocolate as choco
Note that we imported both the sklearn.metrics.precision_score() and
sklearn.metrics.recall_score() metrics. The train function is almost
identical to the realistic tutorial,
except for the two losses.
def score_gbt(X, y, params):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
gbt = GradientBoostingClassifier(**params)
gbt.fit(X_train, y_train)
y_pred = gbt.predict(X_test)
return -precision_score(y_test, y_pred), -recall_score(y_test, y_pred)
Is that it? Yes! This is the only modofication required to optimize over multiple objectives (in addition to using a multi-objective capable search algorithm).
Then we will load our dataset (or make it).
X, y = make_classification(n_samples=80000, random_state=1)
And just as in the Basics tutorial, we’ll decide where the data is stored and the search space for the algorithm. We will optimize over a mix of continuous and discrete variables.
conn = choco.SQLiteConnection(url="sqlite:///db.db")
s = {"learning_rate" : choco.uniform(0.001, 0.1),
"n_estimators" : choco.quantized_uniform(25, 525, 25),
"max_depth" : choco.quantized_uniform(2, 10, 2),
"subsample" : choco.quantized_uniform(0.7, 1.05, 0.05)}
Finally, we will define our search algorithm, request a set of parameters to test, get the loss for that set and signify it to the database.
sampler = choco.MOCMAES(conn, s, mu=5)
token, params = sampler.next()
loss = score_gbt(X, y, params)
sampler.update(token, loss)
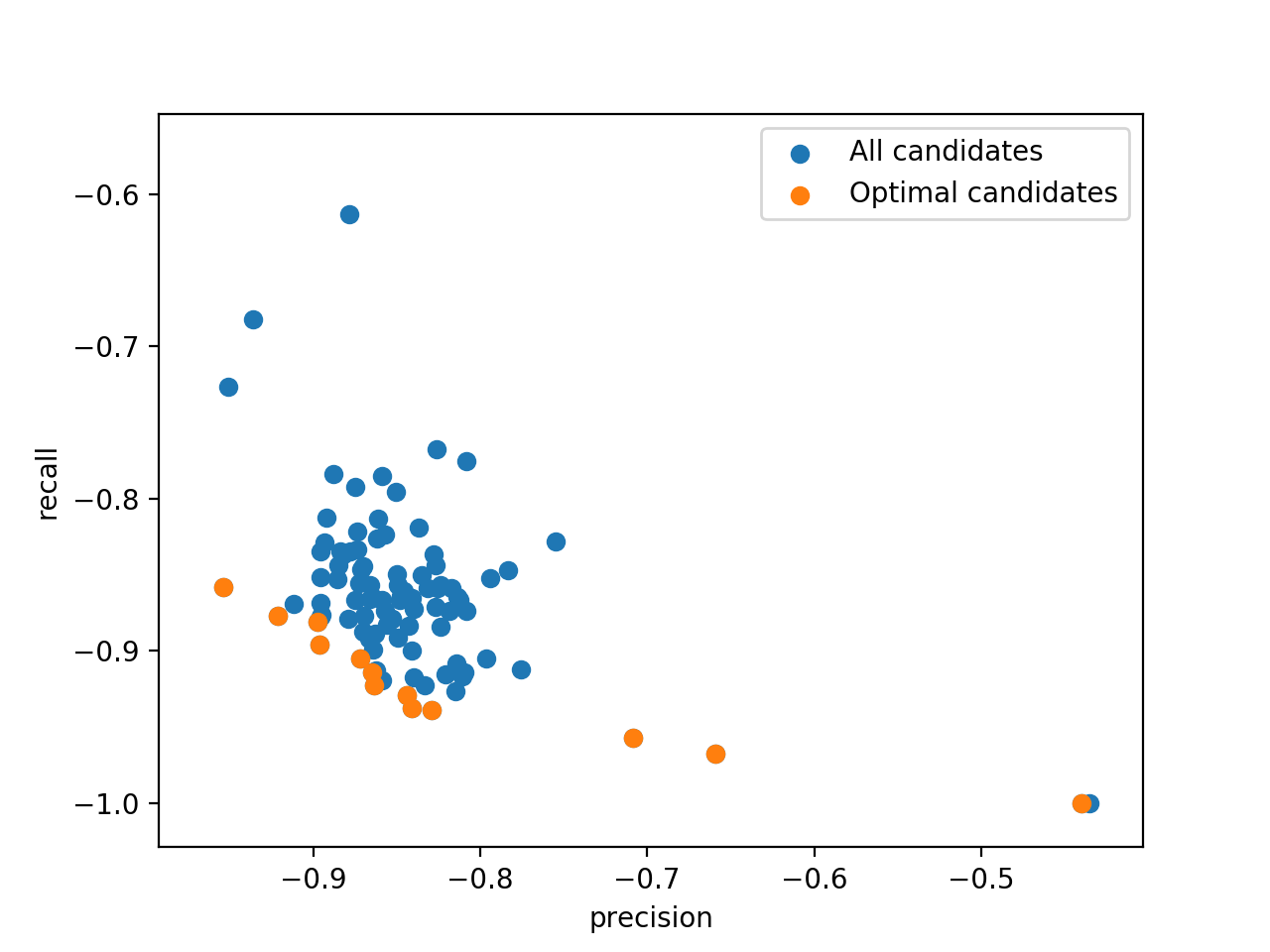
Once this script has run a couple of times, the results can be retrieved. Obviously,
we cannot find THE ULTIMATE configuration in our database since multi-objective
optimization is all about compromise. In fact, the result of the optimization is a
Pareto front containing all
non dominated compromises between the objectives. You can easily retrieve these
compromises using the results_as_dataframe()
method of your connection. To find the Pareto optimal solutions use
chocolate.mo.argsortNondominated() function as follow.
conn = choco.SQLiteConnection(url="sqlite:///db.db")
results = conn.results_as_dataframe()
losses = results.as_matrix(("_loss_0", "_loss_1"))
first_front = argsortNondominated(losses, len(losses), first_front_only=True)
This front can be plotted using matplotlib.
plt.scatter(losses[:, 0], losses[:, 1], label="All candidates")
plt.scatter(losses[first_front, 0], losses[first_front, 1], label="Optimal candidates")
plt.xlabel("precision")
plt.ylabel("recall")
plt.legend()
plt.show()
And, we get this nice graph: